Preprint
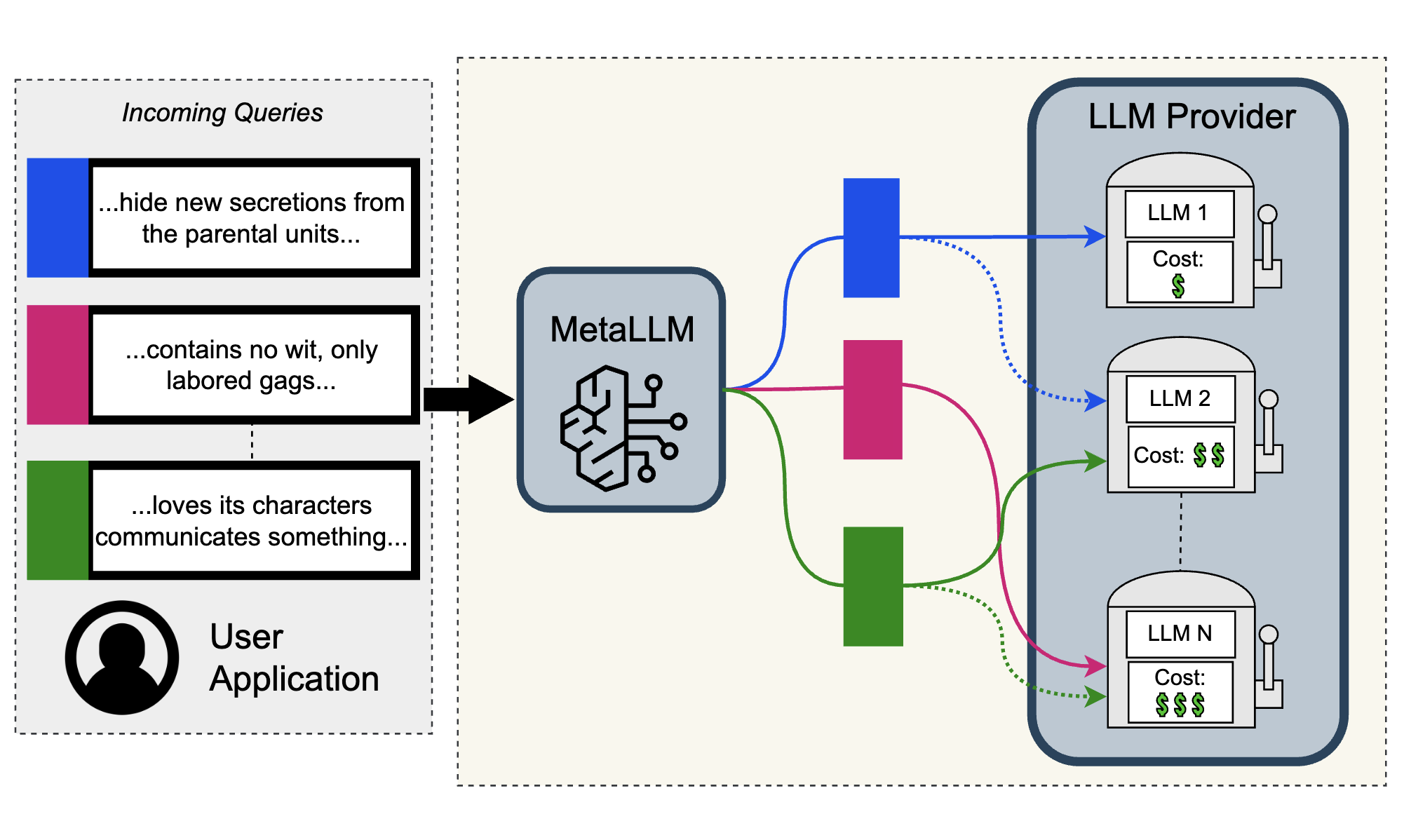
MetaLLM: A High-performant and Cost-efficient Dynamic Framework for Wrapping LLMs
Quang H. Nguyen, Thinh Dao, Duy C. Hoang, Juliette Decugis, Saurav Manchanda, Nitesh V. Chawla, Khoa D. Doan
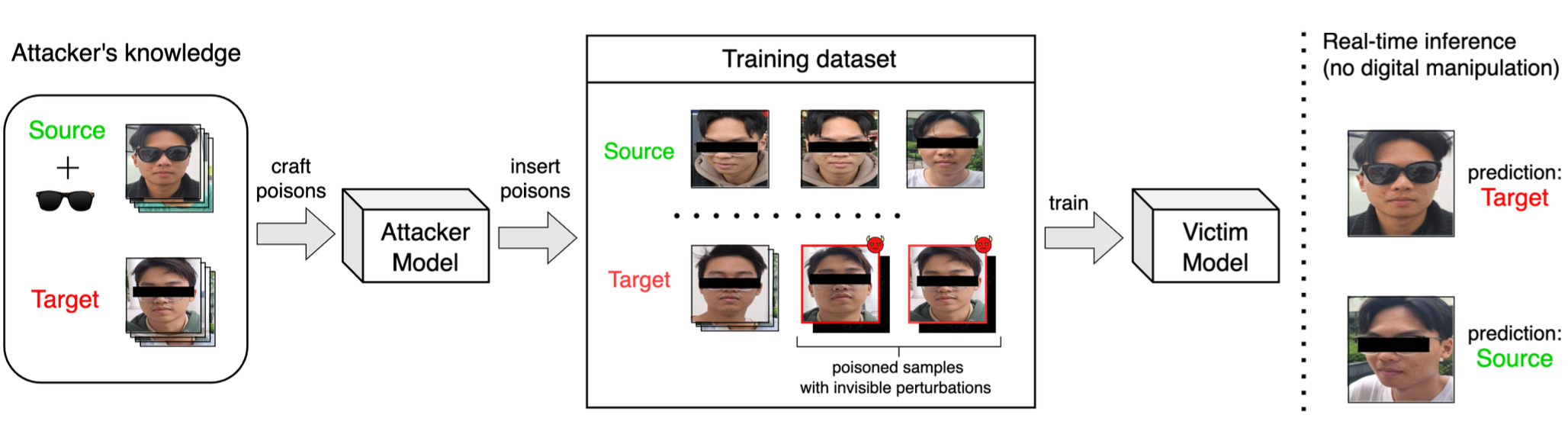
Federated Learning (FL) systems are vulnerable to backdoor attacks, where adversaries train their local models on poisoned data and submit poisoned model updates to compromise the global model. Despite numerous proposed attacks and defenses, divergent experimental settings, implementation errors, and unrealistic assumptions hinder fair comparisons and valid conclusions about their effectiveness in real-world scenarios. To address this, we introduce BackFed - a comprehensive benchmark suite designed to standardize, streamline, and reliably evaluate backdoor attacks and defenses in FL, with a focus on practical constraints. Our benchmark offers key advantages through its multi-processing implementation that significantly accelerates experimentation and the modular design that enables seamless integration of new methods via well-defined APIs. With a standardized evaluation pipeline, we envision BackFed as a plug-and-play environment for researchers to comprehensively and reliably evaluate new attacks and defenses. Using BackFed, we conduct large-scale studies of representative backdoor attacks and defenses across both Computer Vision and Natural Language Processing tasks with diverse model architectures and experimental settings. Our experiments critically assess the performance of proposed attacks and defenses, revealing unknown limitations and modes of failures under practical conditions. These empirical insights provide valuable guidance for the development of new methods and for enhancing the security of FL systems.